Doc As Code: диаграммы PlantUML в Doxygen
Включаем поддержку UML-диаграмм в Doxygen и размышляем о последствиях
На GitHub есть форма для загрузки файлов в репозиторий. Форма очень похожа на Google-диск и провоцирует загружать все подряд. Выбрал файлы, кликнул “Commit changes” и готово, проект загружен. Такие репозитории хорошо видно по стандартным сообщениям коммитов типа “Add files via upload”. А присутствуют в них как файлы исходных кодов, так и полное содержимое сборочных каталогов debug и release.
Давайте разберемся, почему плохо использовать GitHub как Google-диск и как делать правильно.
Когда мы коммитим в репозиторий все подряд, мы получаем как минимум три проблемы.
Размер репозитория растет как на дрожжах из-за обилия бинарных файлов. Почему это так?
Все просто: репозиторий Git хранит историю изменений каждого файла.
В случае текстового файла Git может вычислить различия его новой и старой версии и эффективно сжать данные. Но с бинарными файлами (типа .exe, .dll, .so и т.п.) сжатие работает гораздо хуже. Большие бинарные файлы или большие изменения вообще могут сохраняться отдельными копиями файлов.
Даже если удалить файл из репозитория следующим коммитом, то в истории коммитов он все равно останется и все равно будет занимать место.
Ситуация усугубляется при совместной разработке, когда несколько человек работают над одним репозиторием. Представьте, что каждый коммитит свою версию бинарных файлов, соответствующих свой среде разработки! Подозреваю, репозиторий будет “толстеть” по экспоненте…
У каждого программиста свои настройки среды разработки. Если в репозитории хранятся какие-либо файлы этих настроек, то другие программисты будут вынуждены постоянно бороться с проблемами их несовместимости. Элементарное несовпадение путей к файлам надолго остановит работу.
Ситуация. Первый разработчик коммитит настройки своей любимой IDE. Второй, получив этот репозиторий, не может собрать проект - пути в настройках не соответствуют его системе. Он правит конфиги и коммитит их. Первый тянет обновления и… Думаю, вы поняли. Круговорот конфигов в репозитории обеспечен.
Не стоит хранить в репозитории конфигурацию среды разработки или среды выполнения. А если хочется дать пример конфигурации, то для этого подойдет README-файл.
Вместе с конфигурациями в репозиторий могут попасть секреты. Например, ключи API, логины, пароли и т.п. То есть все, что вы не хотели бы показать третьим лицам.
Секреты могут храниться в конфигурационных файлах прямо в папке проекта. Думаю, не нужно объяснять, к чему может приводить их компрометация.
Размещаем в репозитории только исходные файлы и никаких производных от них.
Под производными файлами понимаем:
.exe) и библиотеки (.dll, .so)..obj) и статические библиотеки (.lib, .a). Если используются системы сборки, например, CMake, то сюда же включаются файлы типа Makefile.Этот список не исчерпывающий, но суть, я думаю, вы уловили.
Когда не понятно, исходный это файл или производный, то можно использовать такой маркер: если какой-то файл вы не изменяли, но при коммите видите его измененным, то это производный файл и его не надо хранить в репозитории.
Да, иногда специфика проекта может потребовать хранения производных файлов. Но это, как правило, специфика.
В репозитории не должно быть ничего специфичного конкретной среде разработки: абсолютные пути к файлам, переменные окружения, настройки IDE, секреты и т.п.
Рассмотрим примеры:
.env.vscode, если используете VS Code*.user, если используете QtCreator.venv, если работаете с PythonФайл .gitignore, размещенный в корне репозитория, показывает git, какие файлы не могут быть закоммичены. С его помощью мы можем предостеречь себя и коллег от случайного размещения ненужных файлов в репозитории.
Git не даст добавить в коммит (git add) файлы с именами или путями, соответствующими паттернам в .gitignore.
Например, так .gitignore может выглядеть на проекте C++:
build*/
*.txt.user
DoxygenDocumentation
А так - на Python:
*build
*dist
.vscode
.venv
*.spec
__pycache__
translations/*.qm
Output
.coverage*
unit_test_*
Резюмируя, можно сказать, что нет единых правил, определяющих содержимое репозитория. Добавлять или не добавлять тот или иной файл в коммит - зависит от стека технологий, проекта и его соглашений. В конечном итоге мы руководствуемся нашими удобством, безопасностью и производственной необходимостью.
А если хочется загрузить в репозиторий все подряд как на Google-диск, то лучше действительно использовать Google-диск.
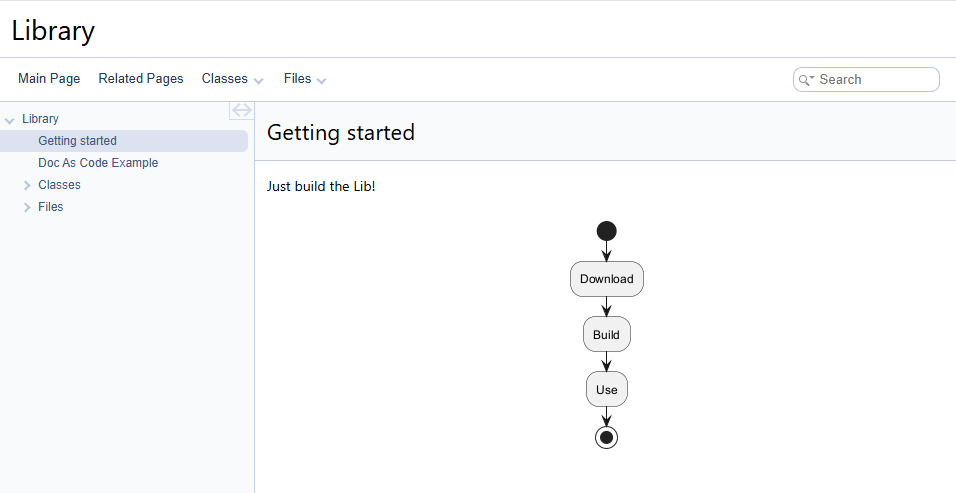
Включаем поддержку UML-диаграмм в Doxygen и размышляем о последствиях
Разбираемся, как не превратить репозиторий Git в Google-диск
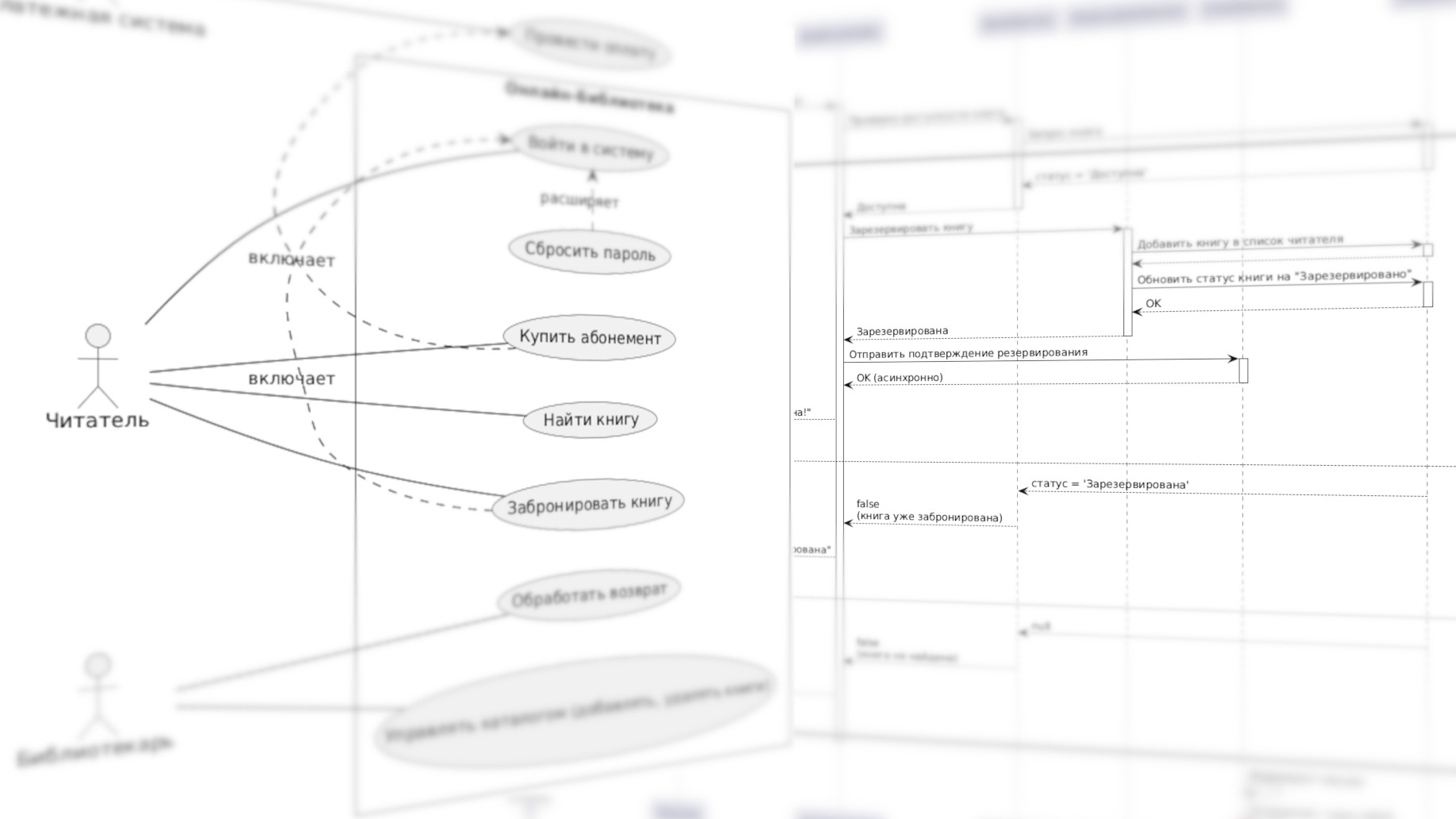
Выясняем, когда и для чего разработчики используют UML
Разделяем на подпроекты существующий проект C++ на CMake
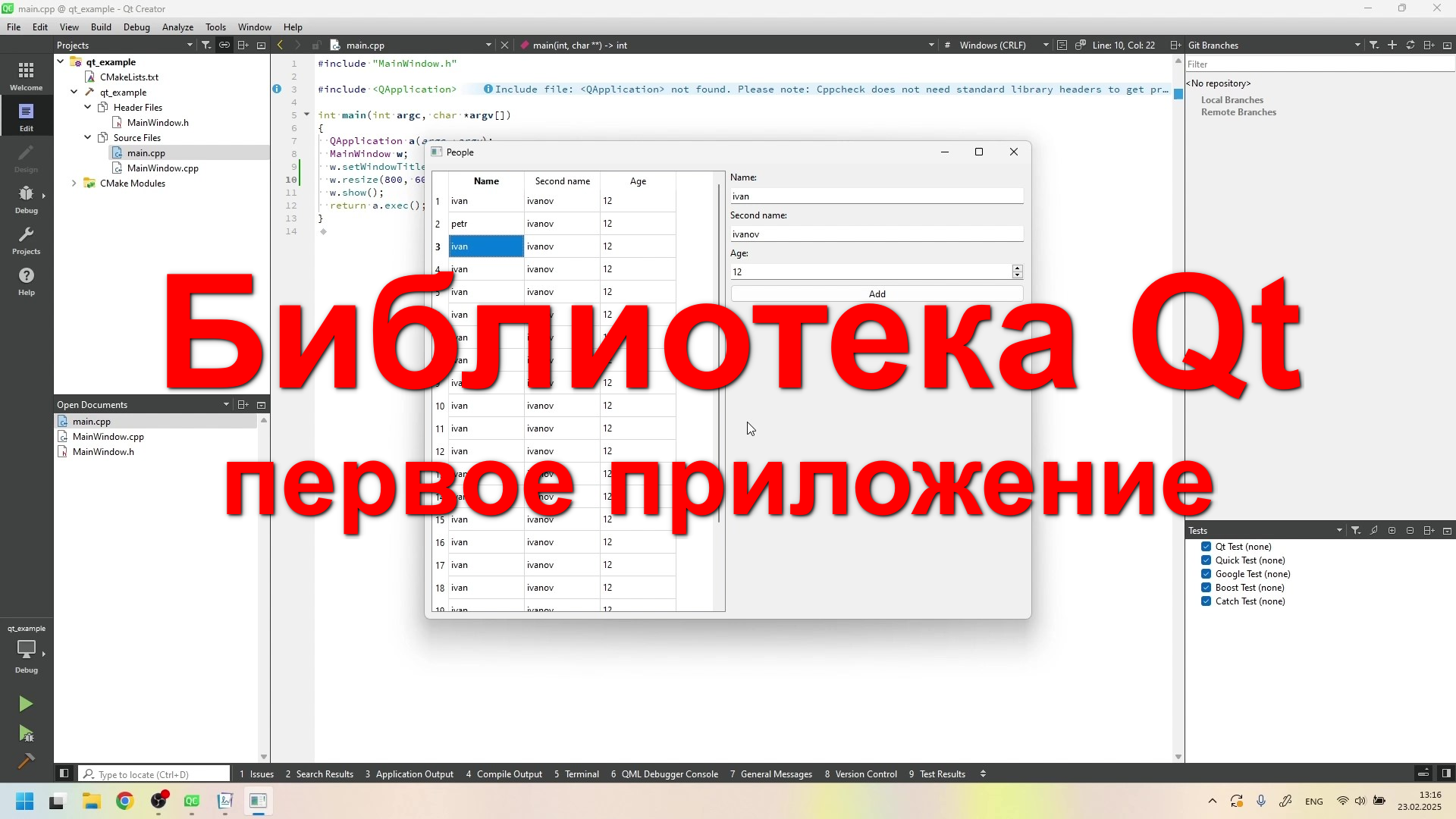
Учимся создавать свое первое оконное приложение на Qt с использованием QMainWindow в среде QtCreator